收获不止Oracle读书笔记
前言
- 20%的知识解决80%的问题,要有侧重点的读书。
- 人的精力是有限的,学习知识的时候要尽量理解原理而不强记。
- 知识要落地,要思考应用的场合。(没想过所学的某项技术有什么用,没想过如何落地,如何应用到实际工作中,都是无意义的学习,纯粹是浪费生命)
- 故事总结:
- 少做暂时无用的事 (有目的的学习,要用到实际中来)
- 少做暂时无意义的事 (不要为了学习而学习)
- 少做错误的事 (考虑应用场景)
- 少让他人做无所谓的事 (能搜别问,问过别问,表述不清别问)
- 表述清楚,少做无谓的交互之事 (问题具体细节表述清楚)
- 流程控制,少做失败的事。(操作前确认步骤,别想当然就执行)
角色分类
- 基础原理:体系结构、物理结构、表、索引、事务
- 开发技能:sql、pl/sql、常用函数
- 管理知识:用户及权限管理、安装调试、备份恢复、数据迁移、闪回、故障处理
- 优化原理:统计信息、执行计划、诊断工具、深入理解表、深入理解索引、表连接原理
- 设计相关:模型工具使用、规范制定执行、业务理解、各类知识综合应用
作为一个开发,需要掌握的知识点有 1、2两点外还要掌握数据库优化原理中的【执行计划】【深入理解表】【深入理解索引】【表连接原理】

知识获取途径:官方文档(其中concept需要反复阅读)、书籍、搜索、培训等。
物理体系结构
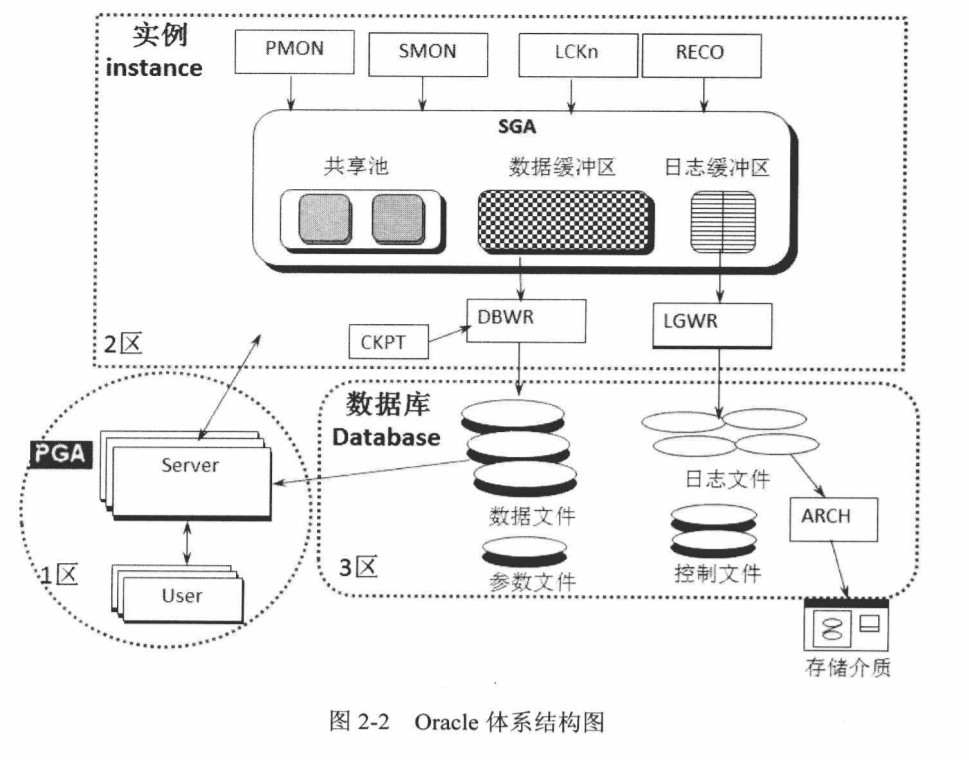
oracle 由实例和数据库组成。
实例是由一个开辟的共享内存区SGA(System Global Area)和一系列后台进程组成。
- SGA划分为共享池(shared pool)、数据缓冲区(db cache)、日志缓冲区(log buffer)三部分。
- 后台进程包含途中实线框中PMON、SMON、LCKN、RECO、CKPT、DBWR、LGWR、ARCH等进程。
数据库是由数据文件、参数文件、日志文件、控制文件、归档日志等文件组成,其中归档日志可能会保存到其他存储介质以作备份。
PGA(Program Global Area)是一块开辟的私有内存区。用户对数据库发起的无论是查询还是更新的任何操作,都是由PGA先预处理,然后进入实例区域,由SGA和系列后台进程共同完成用户发起的请求。
PGA作用:
- 保存用户连接信息(会话属性、绑定变量等)
- 保存用户权限等重要信息 (建立连接时,将用户的权限信息查询出来保存在这里)
- 发起指令需要排序时,PGA作为排序区。在内存PGA中放的下排序尺寸,就在PGA中完成,放不下,就在临时的表空间完成排序,即在磁盘上完成排序。
图中表示 1区 2区 3区,在用户请求发起时一般经历 1区–>2区–>3区;或者1区–>2区;
查询执行流程
开启执行计划记录以及执行计划统计: set autotrace on
开启执行时间记录 set timing on
创建表 create table t as select * from all_objects;
创建索引:create index object_id_index t(object_id)
执行查询select object_name from t where object_id = 29
再次执行查询,观察两次查询时间,以及执行统计。
在第一次执行查询时,登录数据库时会将用户信息,权限信息等存到 PGA 区,在执行查询直接从这里拿到信息,避免物理读取,在到SGA区,共享区中看有没有该sql 的Hash,没有的话,校验Sql语法、逻辑、表字段是否存在等,然后Oracle会自己计算走索引还是全表扫描计算出这两个执行计划的花费(COST),根据花费(COST)来确定执行计划,然后生成一份该sql的hash存储到共享区,执行查询时,看数据缓冲区是否有数据,没有的话再到database读取,存到数据缓冲区,然后返回展示。
第二次执行查询,在SGA区共享区中找到了该sql对应的Hash,直接执行之前保存的执行计划,在数据缓冲区找到上一次的数据就直接从数据缓冲区里拿,不再物理读取数据库。所以第二次执行会快很多。
更新执行流程
更新一条数据 如 update t set object_id = 99 where object_id = 29,
- 用户重新登陆的话,用户权限等信息还在PGA区,去查询数据
- 在共享区,校验sql语法,确定执行计划,生成hash等操作
- 从数据库或数据缓冲区中查询到数据
- 修改数据缓冲区的数据,并由 **
DBWR**进程写入Database文件中。
日志缓冲区
用户的所有操作记录都会记录到日志缓冲区,如执行 A:创建表 B:插入数据 C:更新数据
- ABC操作都会记录到日志缓冲区
- 由**
LGWR**写入日志文件中 - 当日志文件 1,2,3,4都写满了后,先将1由**
ARCH**进程保存到外部数据库,再覆盖写到1日志文件中。
当数据库出现问题可以根据日志文件执行相应记录来恢复数据库。
提交
COMMIT 命令执行后,并不是立即触发DBWR将数据保存到数据库中,而是等到数据缓冲区数据到一定大小,再批量写入数据库中,具体触发是由CKPT触发DBWR写入数据库。CKPT触发时间可以通过FAST START MTTR TARGET来调整。
在CKPT触发DBWR写入前,LGWR进程先执行将日志缓冲区的日志缓冲到日志文件,如果日志写入进程LGWR故障,则CKPT触发DBWR失效。
进程概述
PMON: 进程监视器,执行更新时没提交时程序崩溃,PMON会自动回滚,不用人工rollbackSMON: 系统监视器,重点关注 intance recovery ,兼职 清理临时表空间、合并空闲空间等LCKn: 用于实例间的封锁RECO: 分布式数据恢复,处理一个数据涉及A,B,C三个数据库,要A,B,C三个数据库都提交成功才算成功,否则全部回滚CKRT: 用于触发DBWR从缓冲区中写数据到databaseDBWR:CKPT触发DBWR进行写入数据,DBWR写入前先通知LGWR进行日志从缓冲区写到日志文件,写完日志文件后才开始写入数据。LGWR: 将日志从日志缓存区中写入磁盘REDO文件,单线程保证写入顺序,- 每3秒运行一次
- 任何commit 触发运行一次
DBWR写入文件前触发一次- 日志缓冲区满三分之一或满1M触发一次
- 联机日志切换触发一次
ARCH:LGWR要对日志文件覆盖书写时,ARCH完成对原来的日志文件进行转移归档
逻辑体系
数据文件由一系列的表空间(TABLESPACE)组成,表空间由一个或多个段(sagment)组成,段由一个或多个区(EXTENT)组成,而区由最小单位数据(BLOCK)组成。
BLOCK:数据库中BLOCK一般设置为OS块容量的整数倍,以减少IO操作。BLOCK组成成分有:数据块头(common and variable header):包含此块的概况信息(块地址、所属段类型[属于表还是索引])表目录区(table directory):插入一行数据到数据块中,该行数据的表信息存放到该区域行目录区(row directory):存放插入数据行的地址可用空间(fee space):空余空间行数据区(row data):具体行信息或索引的信息(最占空间)
EXTENT:区是数据库分配空间的最小单位。segment创建成功时,会分配一个包含若干个数据块的初始数据库扩展(initial extent)。固定容量(UNIFORM)扩展:由用户指定扩展容量或使用默认扩展大小1M,指定扩展容量至少要包含有5个BLOCK的大小系统管理(AUTOALLOCATE)扩展:系统动态设置最佳的扩展容量。
TABLESPACE:系统表空间、临时表空间、回滚表空间、数据表空间
表设计
普通堆表
- 优点: 语法简单方便、适用于大部分应用场景
- 缺点: 表更新日志开销大、delete无法释放空间、表记录大检索慢、有序读出难
全局临时表
更新删除日志量比普通表少,适合作为临时数据中间表,自动删除数据释放空间
分类:
基于SESSION:on commit preserve rows退出SESSION 表记录删除,每个SESSION的数据独立。基于事务:on commit delete rowscommit或退出SESSION 表记录删除。
分区表
不同的分区,在不同的
SEGMENT中特性:
- 高效的分区消除 (在查询数据在某一分区数据时,消除其他分区的访问)
- 高效的记录清理(
truncate partition p_xx) - 高效的分区转移(
exchange partition part_xx with table mid_table)
分区类型:
RANG分区:范围分区多以时间列进行分区1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18-- 将数据按一年12个月进行分区
create table range_part_table (id number,deal_date date,area_code number, contents varchar2(4000))
partition by range(deal_date)
(
partition p1 values less than(TO_DATE('2020-02-01','YYYY-MM-DD')),
partition p2 values less than(TO_DATE('2020-03-01','YYYY-MM-DD')),
partition p3 values less than(TO_DATE('2020-04-01','YYYY-MM-DD')),
partition p4 values less than(TO_DATE('2020-05-01','YYYY-MM-DD')),
partition p5 values less than(TO_DATE('2020-06-01','YYYY-MM-DD')),
partition p6 values less than(TO_DATE('2020-07-01','YYYY-MM-DD')),
partition p7 values less than(TO_DATE('2020-08-01','YYYY-MM-DD')),
partition p8 values less than(TO_DATE('2020-09-01','YYYY-MM-DD')),
partition p9 values less than(TO_DATE('2020-10-01','YYYY-MM-DD')),
partition p10 values less than(TO_DATE('2020-11-01','YYYY-MM-DD')),
partition p11 values less than(TO_DATE('2020-12-01','YYYY-MM-DD')),
partition p12 values less than(TO_DATE('2021-01-01','YYYY-MM-DD')),
partition p_max values less than(maxvalue)
)partition by range表示范围分区values less than范围分区特定语法,partition p2 values less than(TO_DATE('2020-03-01','YYYY-MM-DD'))表示小于2020-03-01日期的作为一个分区- partition p1 ~ p_max 共 13个分区,且 用
partition p_max values less than(maxvalue)指定不在指定范围内的都归入到p_max分区防止报错 - 不同的分区可指定到不同的表空间中
LIST分区:列表分区,常以固定已知列作为分区列(如地区编码,单位编码等)1
2
3
4
5
6
7
8-- 以不同的地区号进行列表分区
create table list_part_table(id number,deal_date date,area_code number, contents varchar2(4000))
partition by list(area_code)(
partition p_10110 values (10110),
partition p_10210 values (10210),
partition p_10310 values (10310),
partition p_other values (default)
)partition by list:列表分区关键字vuales:为列表分区的固定写法,partition p_10210 values (10210)表示area_code == 10210 的数据都会放到此分区中。也可以指定多个值如partition P_1030_1040 values(1030,1040)- partition p_10110 ~ p_other 共创建了4个分区,其中 P_other 的 default 写法把不指定分区的数据都落到此分区,防止出错
- 不同的分区可指定到不同的表空间中
HASH分区:散列分区1
2
3
4-- 创建一个12个分区的散列分区表
create table hash_part_table(id number,deal_date date,area_code number,contents varchar2(4000))
partition by hash (deal_date)
partitions 12;partition by hash表示创建的是散列分区partitions 12无需指定分区名,直接指定分区个数,尽量指定偶数个STORE IN (TS1,TS2,TS3,....TS12)可以通过该语句指定不同分区的表空间
组合分区:范围-列表(range-list)、范围-散列分区、范围-范围分区、列表-哈希分区等1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26-- 创建范围-列表 组合分区
create table range_list_part_table(id number, deal_date date, area_code number, contents varchar2(4000))
partition by range(deal_date)
subpartition by list(area_code)
subpartition TEMPLATE
(
subpartition p_1010 values (1010),
subpartition p_2010 values (2010),
subpartition p_3010 values (3010),
subpartition p_other values (default)
)
(
partition p1 values less than(TO_DATE('2020-02-01','YYYY-MM-DD')),
partition p2 values less than(TO_DATE('2020-03-01','YYYY-MM-DD')),
partition p3 values less than(TO_DATE('2020-04-01','YYYY-MM-DD')),
partition p4 values less than(TO_DATE('2020-05-01','YYYY-MM-DD')),
partition p5 values less than(TO_DATE('2020-06-01','YYYY-MM-DD')),
partition p6 values less than(TO_DATE('2020-07-01','YYYY-MM-DD')),
partition p7 values less than(TO_DATE('2020-08-01','YYYY-MM-DD')),
partition p8 values less than(TO_DATE('2020-09-01','YYYY-MM-DD')),
partition p9 values less than(TO_DATE('2020-10-01','YYYY-MM-DD')),
partition p10 values less than(TO_DATE('2020-11-01','YYYY-MM-DD')),
partition p11 values less than(TO_DATE('2020-12-01','YYYY-MM-DD')),
partition p12 values less than(TO_DATE('2021-01-01','YYYY-MM-DD')),
partition p_max values less than(maxvalue)
)subpartition by list指定从分区,partition by range指定主分区subpartition TEMPLATE避免每个主分区都写相同的从分区
分区操作
1
2
3
4
5
6
7
8--切割
alter table range_part_table split partition p_max at (TO_DATE("2021-02-01",'YYYY-MM-DD')) into (partition p2020_02, partition p_max)
--合并
alter table range_part_table merge partition p2020_02,p_max Into partition p_max
--删除
alter table range_part_table drop partition p_max
--添加 (最后一个分区为 maxvalue时只能切割不能添加,或者先删除maxvalue分区再添加)
alter table range_part_table add partition p14 values less than (TO_DATE('2020-03-01','YYYY-MM-DD'));分区索引:
1
2
3
4-- 全局索引 (全局分区的大索引)
create index idx_part on range_part_table(deal_date);
-- 局部索引 (每个分区的小索引)
create index idx_part on range_part_table(deal_date) local;分区表相关易错:
1
2
3
4
5-- 操作分区导致全局索引失效
-- 重建全局索引
alter index idx_part rebuild;
-- 操作分区表后默认自动重建索引 update global indexes
alter table range_part_table truncate partition p2 update global indexes;
索引组织表
可以在查询某个索引数据时,不回读原来的表获取其他列的数据,提高读的效率,但是写入效率低下。索引组织表本身即是索引也是表。在数据很少变动的情况,而且需要读的情况非常多,如地区编号等,这种可以用索引组织表。
1 | -- 创建索引组织表 |
簇表
默认有序的表,可以保证表数据的有序,但是由于该表的特殊结构,导致更新操作开销非常大,慎用。
1 | -- 创建一个簇表 |
索引
BTREE索引
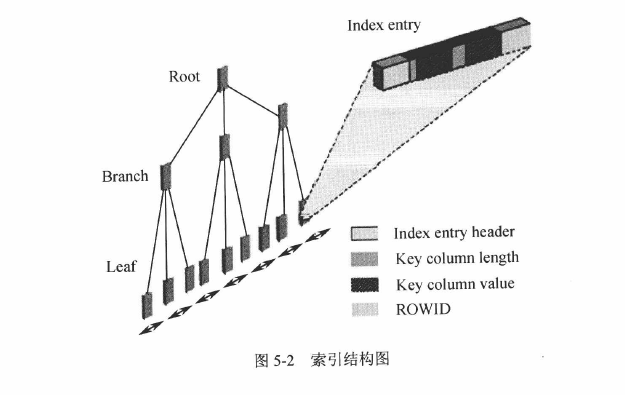
索引由Root(根)、Branch(茎)、Leaf(叶子块)三部分组成,对一列键索引就会产生一个索引segment。
Leaf中主要存储了key column value(索引列的具体值) 、rowID(定位该行所在位置的RowId,可用于查找该行非索引列的数据)- 建索引时,会对所有数据进行排序,然后依次将数据放到
block数据块中,形成一个个Leaf,在很大量数据时,会在生成一个个block块Branch,用于存储多个Leaf块的地址,如果Branch都不够保存,就会向上生成一个block块(root)来保存Branch的地址。
假如索引查询select * from t where id = 12需要3个IO,则索引查询如下图(一般1万多条记录仅需要2次IO)
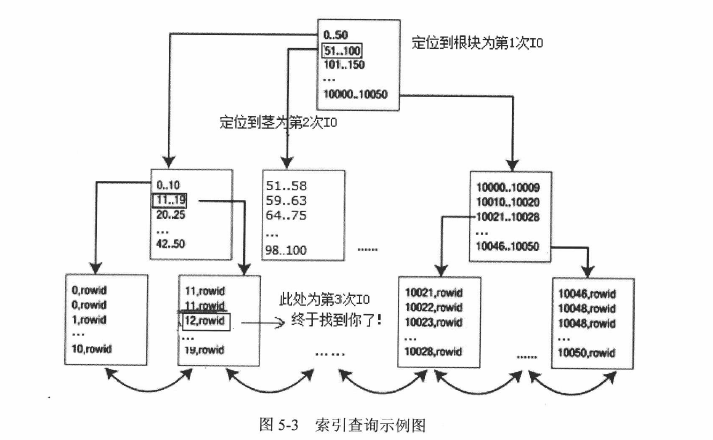
索引高度较低:从索引结构可以看出,这种金字塔结构的索引高度不高(500G数据的(几百亿条数据)表高度大概6层)
索引存储列值: 索引中存储了索引列中的值,在查询单个索引列数据时不需要回读表获取数据。
索引本身有序: 索引构建过程是按顺序插入数据块中。
索引高度对表数据的优化:
分区索引中局部索引、全局索引、和普通表索引。查询一个有12个分区的分区表,用局部索引每个索引高度为2的话,要经历遍历的 N*2 次IO,而用全表索引可能只需要经历2次IO。所以用局部索引时要加上分区条件,这样就仅需要经历该分区的索引,2次IO即可。
count(*)优化: 在
t表中的id列建一个索引。select count(*) from t这条语句并不会默认走索引,select count(*) from t where id is not null这条会走索引,不写id is not null则需要在建表时指明该列not null属性、或指明该列是主键。SUM/AVG优化:在
t表中id列建索引。select sum(id) from t这条语句需要指定为select sum(id) from t where id is not null才会走索引查询。MAX/MIN优化: 在
t表中id列建索引。select max(id) from t、select min(id) from t都默认走索引INDEX FULL SCAN(MIN/MAX),分别取索引最右和最左(索引有序 Asc)。select max(id),min(id) from t走的是全表扫描TABLE ACCESS FULL,而select max(id),min(id) from t where id is not null走的是INDEX FAST FULL SCAN,推荐分别用两条语句查出最大最小值合并的写法来优化。索引回表优化:消除
TABLE ACCESS BY INDEX ROWID,适当将需要的列做成组合索引(需要返回数据超过3个则不适合用组合索引)。索引是有序的,表数据的排列顺序和索引的排列顺序匹配,看看双方差异(聚合因子),越匹配查询耗费越低,所以可以通过重组表记录来优化。order by优化:索引本身有序,在需要order by 的字段中建索引可以提升性能。
Distinct重排优化:DISTINCT会因为排序而影响性能,但是通过建索引来优化效果不大。
INDEX FAST FULL SCAN: 无需排序的查询(如count(*),sum(id))会用到,一次读取多个索引block。INDEX FULL SCAN: 需要有序的插叙会用到,按顺序读取索引block。Union和Union ALL: 将根本无重复数据的表用
UNION ALL替换UNION表外键上建索引组合索引前后: 等值查询效率一样,当一列是范围查询,一列是等值查询时,等值查询列在前,范围查询列在后,索引效率会更高。如果单列查询列和联合索引的前置列一样,那单列可以不建索引,直接利用联合索引来进行检索数据。
- 索引对数据的插入更新效率都有影响,对于庞大数据插入,可以先失效索引,插入完成后再重建索引。
位图索引
位图索引适用场景:①位图索引列大量重复(如people表的sex列)。②该表极少更新(更新位图列会锁表)
函数索引
列运算会让索引失效,此时可以建函数索引。函数索引性能在全表扫描和普通索引之间。应尽量减少列运算,少建函数索引,而转化成普通索引。
表连接
嵌套循环连接(Nested Loops Join)
从一个表中获取一条数据再用这条数去循环匹配另一张表的数据,在查询少量数据时,效率更高。
存在t1,t2表,执行下面语句leading(t1)为指定t1表作为驱动表,use_nl为指定用嵌套循环连接。
1 | select /*+leading(t1) use_nl(t2) */ * from t1,t2 where t1.id = t2.id |
通过执行计划select * from table(dbms_xplan.display_cursor(null,null,'allstats last'))可以看出,t1总被访问一次,t2访问t1记录的行数的次数。
在嵌套连接中,驱动表返回多少条记录,被驱动表就访问多少次
嵌套连接,支持所有条件连接,无限制。
哈希连接(Hash Join)
存在t1,t2表,执行下面语句leading(t1)为指定t1表作为驱动表,use_hash(t2)为指定哈希连接。
1 | select /*+leading(t1) use_hash(t2) */ * from t1,t2 where t1.id = t2.id |
在哈希连接中,驱动表和被驱动表都会只访问0次或1次
哈希连接,不支持 <> > < like连接,即连表时用where t1.id > t2.id是支持哈希连接的
排序合并连接(Merge Sort Join)
1 | select /*+ordered use_merge(t2) */ * from t1,t2 where t1.id = t2.id |
在排序合并连接中,T1表和T2表都只会访问0次或者1次(无驱动和被驱动的概念)
排序合并连接,不支持 <> like连接,但支持> <连接




